[CC] cheat’s Q&D Hadoop 0.23.6 install guide
Hadoop is one of the most popular open source “Cloud Computing” platforms that is used to crunch massive amount of data on generic hardware (computer hardware that is non-proprietary and not necessary has to be identical). It is not exactly “Cloud Computing” per se, because it is a computing architecture that is meant for processing massively large amount of data in parallel. Taxonomically, Parallel Computing (the predecessor to cloud computing) would be the closer terminology. Hadoop comes with several features, most notably the HDFS (Hadoop File System), and MapReduce. I attempt to describe HDFS, and MapReduce in a one liner. HDFS: it is an open source cousin of GFS (Google File Systems), provides a framework to manage data redundancy, and most importantly the scalability is as simple as adding more generic hardware. MapReduce: it is a programming model for processing very large amount of data that leverages on the classic computing method: the divide and conquer approach through the Map stage follow by the Reduce stage. On top of that, it performs sorting intrinsically via the programming model. Oh wait… I busted my one liner quota for MapReduce.
Back in late 2012 I have followed the text book example and played with Hadoop 0.20.0. Setting up and Installation is a breeze, due to the fact that many user guide and tutorials that are made available by the community. In early 2013, Hadoop 0.23.6 come by and I assumed the installation is going to be identical to the earlier version, but I was wrong. As a matter of fact, I have used some nonstandard way by the tree command to find the changes in directory for the necessary configuration files. If the version documentation rocks at that time, it will really save me some of my hair.
Hadoop 0.23.6 is an interesting release. In this version, several major changes/overhaul are made. Most notably, the API call of HADOOP.MAPRED is deprecated and superseded by HADOOP.MAPREDUCE aka MRv2. Resource management of a Hadoop Cluster was relegated to a dedicated service named YARN. Several advanced data structures meant for programming MapReduce were added; some were deprecated (I will go into the details of implementation in the future posts).
For a complete genealogy of Hadoop versions, check this out.
Hadoop 0.23.6 is an interesting release. In this version, several major changes/overhaul are made. Most notably, the API call of HADOOP.MAPRED is deprecated and superseded by HADOOP.MAPREDUCE aka MRv2. Resource management of a Hadoop Cluster was relegated to a dedicated service named YARN. Several advanced data structures meant for programming MapReduce were added; some were deprecated (I will go into the details of implementation in the future posts).
For a complete genealogy of Hadoop versions, check this out.
This install guide assumes
- Ubuntu server 11.x on a VM; I have used 40GB for a start, but run out very quickly.
- Hadoop 0.23.6 in releases
- Java 6 openJDK
- Hadoop cluster lives as a single node
Several things to take note prior to running Hadoop. Locate the directory of configuration files; differentiate between datanode and namenode; dedicate a “Hadoop user”; necessary files permission on the directories; HDFS is not your regular file system, it requires a separate software to access; Hadoop starts with a daemon;
Step1: Download Hadoop and extract it to a directory.
Then name of the directory with the files extracted shall be used in all of the following config. E.g I have created a folder “/usr/local/hadoop” and the files are extracted in it.
Step2: Locate the configuration templates, and directory to place the configurations
#template
/usr/local/hadoop/share/hadoop/common/templates/conf
#path to place configuration files
/usr/local/hadoop/etc/hadoop
Step3: create directory for temporary files, logs, namenode, and datanode
/usr/local/hadoop/data/hdfs/datanode
/usr/local/hadoop/data/hdfs/namenode
/usr/local/hadoop/data/hdfs
/home/user/hadoop/tmp
#output for hadoop logs
/user/user
Step4: copy example configuration templates to config directory and then edit the configuration files.
Configuration files needed are “yarn-site.xml;core-site.xml;hdfs-site.xml;mapred-site.xml”. Put in the parameters as per required in to the configuration files mentioned above. A sample of the configured configuration files are available to download here.
Step5: add the necessary paths and verify the paths
#path to add to ~/.bash
$JAVA_HOME=/usr/lib/jvm/java-6-openjdk
$HADOOP_HOME=/usr/local/hadoop
# update the paths
source ~/.bash
#Verify the paths
#output should be similar to the following
share/doc/hadoop/api/org/apache/hadoop/examples
/usr/local/hadoop/hadoop/hadoop-0.23.6/share/doc/hadoop/api/org/apache/hadoop/examples
/usr/local/hadoop/share/hadoop/hadoop-0.23.6/share/doc/hadoop/api/org/apache/hadoop/examples
/usr/local/hadoop/share/doc/hadoop/api/org/apache/hadoop/examples
/usr/local/hadoop/share/hadoop/hadoop-0.23.6/share/doc/hadoop/api/org/apache/hadoop/lib
/usr/local/hadoop/share/hadoop/hadoop-0.23.6/share/hadoop/mapreduce/hadoop-mapreduce-client-core-0.23.6.jar
/usr/local/hadoop/share/hadoop/hadoop-0.23.6/share/hadoop/mapreduce/hadoop-mapreduce-client-common-0.23.6.jar
Step 6: Format name node
Warning: this step only requires to be done ONCE for each newly setup cluster. Executing this command on an existing cluster will risk data loss.
#do once only, at the initial setup of hadoop
bin/hadoop namenode –format
Step 7: Start the daemon for Hadoop
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
Step8: verify Hadoop cluster with jps
Assumed that the setting up and configuration went fine, the following screen will appear after typing the command “jps”.
Step9: verify Hadoop cluster with web based consoles
Note: 192.168.253.130 is the IP address of my Ubuntu server.
#namenode console to verify o/p

#for ResourceManager
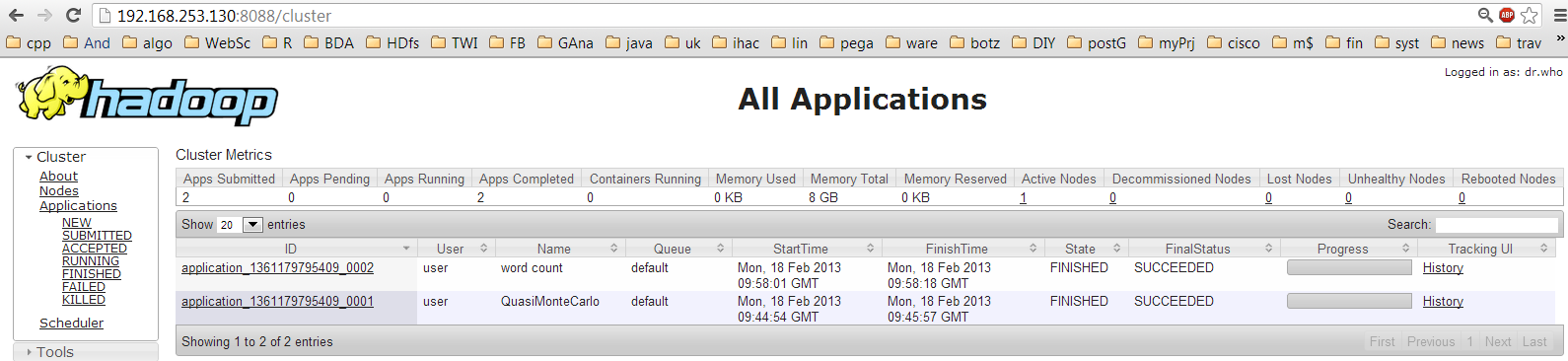
#for Job History Server
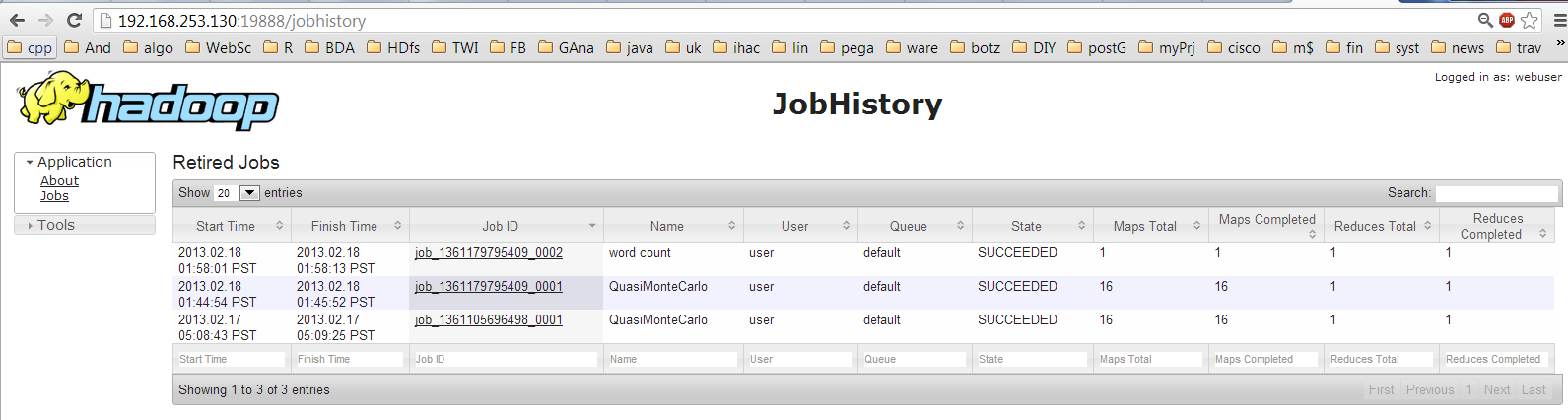
Step10: Verify Hadoop & MapReduce in action
run example word count
#copy text files from “/home/user/upload” to HDFS directory “/user/user/txt”
bin/hadoop dfs -copyFromLocal /home/user/upload /user/user/txt
bin/hadoop dfs -ls /user/user/txt
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-0.23.6.jar wordcount /user/user/txt /user/user/txt-output
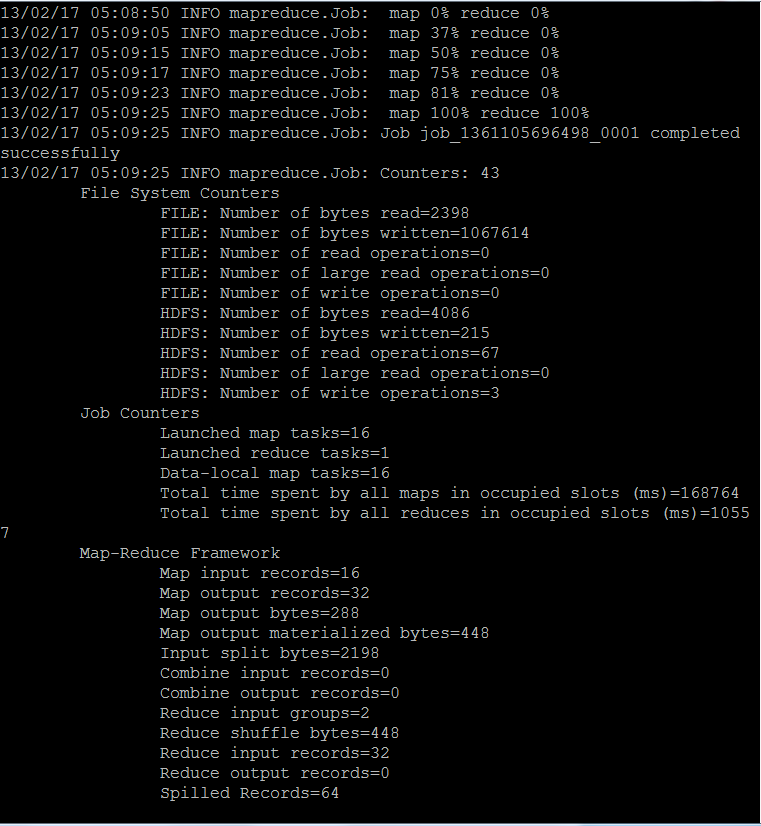
calculate pi
#run an example calc pi
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-0.23.6.jar pi -Dmapreduce.clientfactory.class.name=org.apache.hadoop.mapred.YarnClientFactory -libjars share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-0.23.6.jar 16 10000

Compile a custom word count in java with MapReduce on Hadoop 0.23.6
#to compile
javac -classpath /usr/local/hadoop/share/hadoop/hadoop-0.23.6/share/hadoop/common/hadoop-common-0.23.6.jar:/usr/local/hadoop/share/hadoop/hadoop-0.23.6/share/hadoop/common/lib/commons-cli-1.2.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-common-0.23.6.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-0.23.6.jar -d classes WordCount.java && jar -cvf wordcount.jar -C classes/
#to execute
/usr/local/hadoop/bin/hadoop jar wordcount.jar org.myorg.WordCount /user/user/txt /user/user/bigram-output


Verify output with
/usr/local/hadoop/bin/hdfs dfs -ls /user/user

No comments:
Post a Comment